
Text Normalization for Natural Language Processing using Python NLTK Library and Linux Commands


Randomness in languages is inherent since it's the medium used in communication by all people. Therefore compared with other types of data, languages are prone to more randomness and noise. When we use machine learning models to process large text corpses, it is best that we first deal with minimizing the randomness of the data utilizing normalization in the data preprocessing stage. This article covers how text corpses are normalized, what Linux commands we can use to normalize text and how to use the Natural Language Tool kit (NLTK) in Python for text normalization.
We used the following methods to normalize text corpses: word tokenization, word stemming, and lemmatization.
Word Tokenization
Word tokenization is the process of splitting a large sample of text, such as a text corpus, into individual words. In Python, we can use the Natural Language Tool kit (NLTK) to archive this. We can also use the 'tr' command in Linux to do word tokenization.
To execute the commands in this blog post, download the text corpus from the following link, and save it as 'text.txt'. Text Corpus
We can use the Linux 'tr' command to map characters to another set of characters. For NLP purposes, we would be mapping all upper case characters to lower case characters, and every none character substituted by a newline character. The -s flag is for substitution, and the -c flag is for the complement.
tr -sc 'A-Za-z' '\n' < text.txt | tr -s 'A-Z' 'a-z' | less
The output would be as follows,
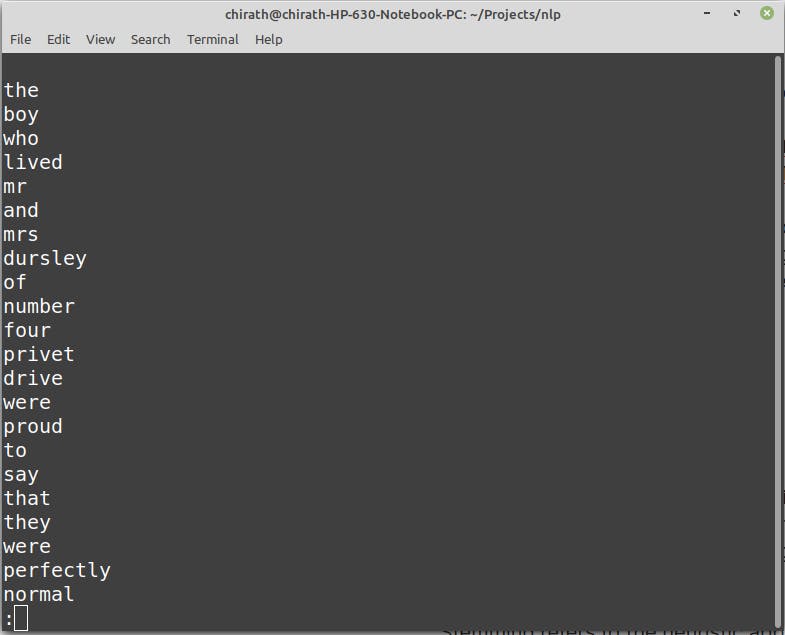
We can then sort the words in alphabetical order using the 'sort' command and find the words' occurrences using the 'uniq' command. The frequency of the particular word token is counted by the -c flag.
tr -sc 'A-Za-z' '\n' < text.txt | tr -s 'A-Z' 'a-z' | sort | uniq -c | less
The output would be as follows,
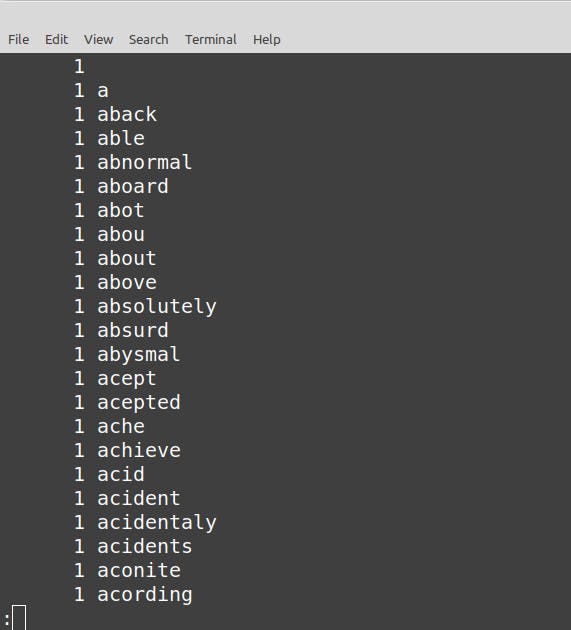
To sort the frequency from the most frequent to the least frequent, we use the sort command with the -n and -r flags. The -n flag would sort numbers, and the -r flag would sort them in descending order (from the highest frequency to the lowest frequency)
tr -sc 'A-Za-z' '\n' < text.txt | tr -s 'A-Z' 'a-z' | sort | uniq -c | sort -nr | less
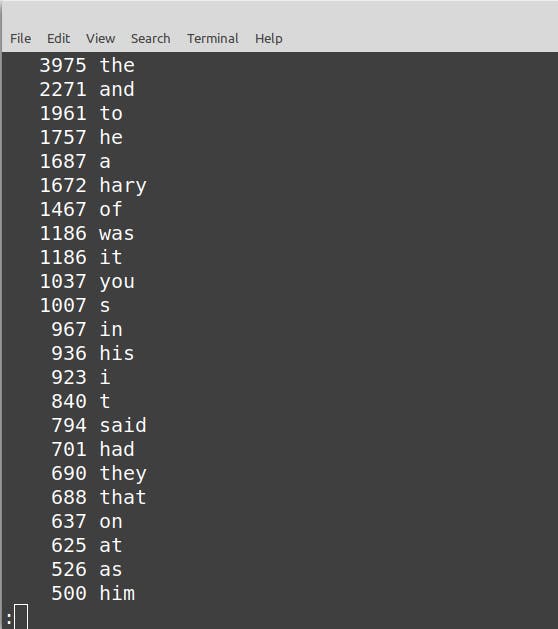
The ouput would be as follows,
We can also write the results instead of using the 'less' command, to a text file, so we can process it further in Python, like so
tr -sc 'A-Za-z' '\n' < text.txt | tr -s 'A-Z' 'a-z' | sort | uniq -c | sort -nr > result.txt
To do word tokenization in Python using the NLTK library is fairly straightforward, once you have installed NLTK on your system, the following code can be executed to get unique words from a text corpus,
import nltk
from nltk.probability import FreqDist
with open("text.txt", "r") as textfile:
data = textfile.read()
tokens = nltk.word_tokenize(data)
data_analysis = nltk.FreqDist(tokens)
print(data_analysis)
filter_words = dict([(m, n) for m, n in data_analysis.items() if len(m) > 3])
for key in sorted(filter_words):
print("%s: %s" % (key, filter_words[key]))
data_analysis = nltk.FreqDist(filter_words)
data_analysis.plot(25, cumulative=False)
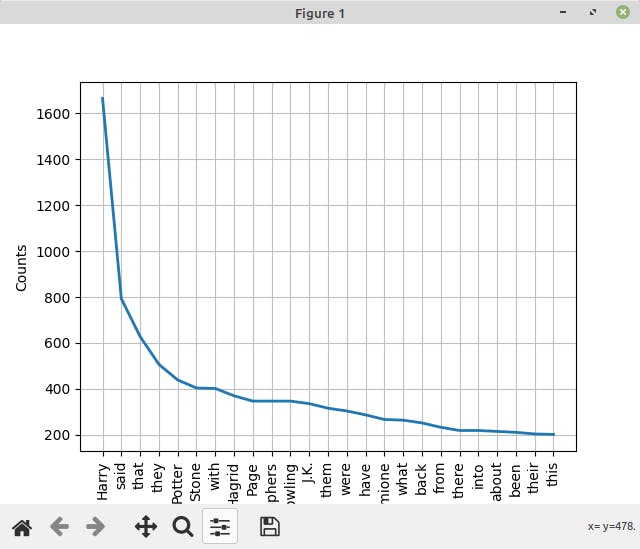
The word tokens are extracted from the text corpus, and their frequency is displayed. The NLTK library also allows you to plot the frequency distribution. For the following text corpus, this is what the frequency distribution might look like,
Stemming and Lemmatization
Because of grammatical reasons, writers can write the same word in different ways. For example, the writer can write the name organize as organizes and organizing. The lemmatization process and stemming are to convert related forms of a word to a common base form.
Stemming refers to the heuristic approach of chopping the ends of the words in the hope of archiving a common base form. A standard algorithm in word-stemming is known as Porter's algorithm.
import nltk
from nltk.stem import PorterStemmer
with open("text.txt", "r") as textfile:
data = textfile.read()
tokens = nltk.word_tokenize(data)
ps = PorterStemmer()
for token in tokens:
print(ps.stem(token))
Lemmatization differs from stemming as these algorithms use a vocabulary and a morphological analysis of words aiming to remove inflectional endings and return's their base form.
import nltk
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet')
with open("text.txt", "r") as textfile:
data = textfile.read()
tokens = nltk.word_tokenize(data)
lemmatizer = WordNetLemmatizer()
for token in tokens:
print(lemmatizer.lemmatize(token))
Thank you for reading until the end, if you have any questions please feel free to leave a comment down below.